Kafka is a distributed append-only log that has become a de-facto standard for real-time event streaming.
Motivation: As software moves from processing static snapshots of state to continuous stream of events, we need a single platform to store and stream events.
Usecases: real-time fraud detection, automotive sensors, IoT, microservices etc.
Concepts
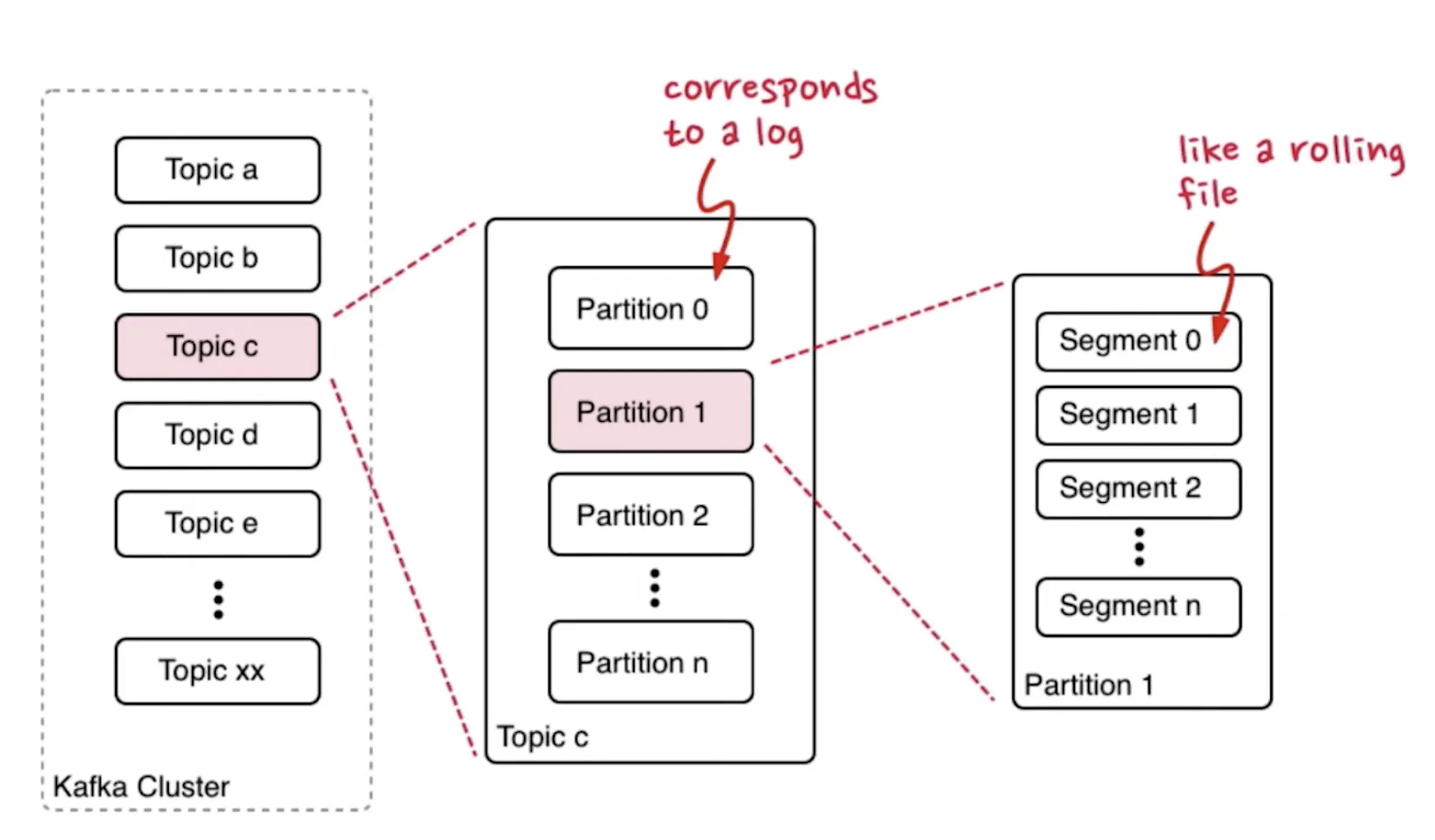
Topics are a stream of “related” messages / events in Kafka. We can create an unlimited amount of topics.
Each topic are broken up into partitions, which are then (replicated and) allocated to separate brokers. Each partition is an ordered, immutable sequence of records that is continually appended to, i.e. a structured commit log.
- Kafka do not guarantee strict ordering in a topic, but it guarantees strict ordering in a partition.
- If you only care about the current state of data, Kafka also provides compact log.
Segments are log segments that is stored by brokers on the disk.
Further readings:
Components
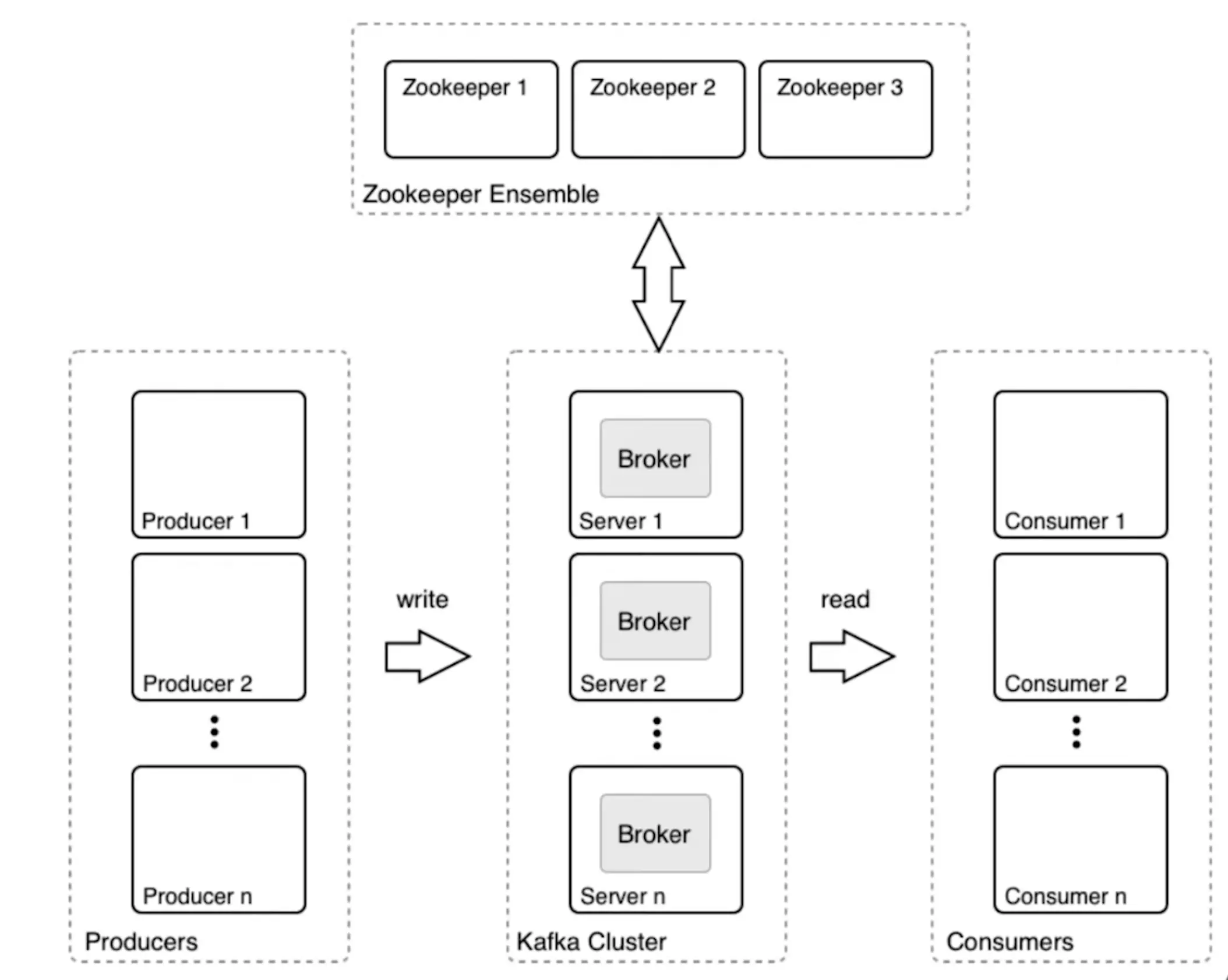
3 fundamental components:
- Producer: an application that we write that puts in data into the Kafka cluster
- Kafka cluster: a cluster of networked brokers, where each broker has its own backing storage.
- Consumer: an application that reads data out of the Kafka cluster. Reading data from Kafka do not remove the message.
Kafka essentially decouples producers and consumers which brings some advantages like slow consumers doesn’t affect producers, consumer failure doesn’t affect system.
Kafka can be used as a queue or a pub-sub system.
Producers
Producers specify a partitioning strategy to assign each message to a partition. The strategy defaults to hash(key) % number_of_partitions or round-robin when key is not specified.
E.g. If we want to maintain ordering of events from the same IoT device, we can use the device_id as the key.
We can specify the producer durability guarantees by specifying NONE (directly replies ACK), LEADER (at least persisted in leader) or ALL.
Brokers
Each broker handles many partitions, each of which are stored on broker’s disk. Each message in log is identified by Offset. In addition to that, we can also configure the retention policy (1 week by default) of data in Kafka.
Each partition is replicated across broker with a configurable replication factor (usually 3), with one of the broker elected as the leader, and the others as follower.
Consumers
Consumers pull messages and new inflowing messages are retrieved (with long-polling mechanism). In addition to that, Kafka keeps track of the last message read by consumer in a _consumer_offset topic.
In Kafka, every consumer belong to a consumer group. In one consumer group, each partition will be processed by one consumer only. When a customer is added / removed from a group, Kafka will automatically rebalance the consumption.
If you create one consumer per group, Kafka behaves like a pub-sub system. Otoh, if you create all customers in 1 group, Kafka behaves like a queueing system.
Delivery Guarantees
Kafka’s delivery guarantees of events can be divided into:
- at most once: useful when we can tolerate some messages being lost
- at least once: useful when events are idempotent
- exactly once: Kafka provides strong transactional guarantees that prevents clients from processing duplicate messages and handles failure gracefully.
Further readings on delivery guarantees :
Data Elements
What is stored inside a data? It is basically a key-value pair.
- Header (optional): contains metadata
- Key: of any type
- Value: of any type
- timestamp: creation / ingestion time
Security
Kafka supports encryption on transit (connections between client - broker, broker - broker, broker - zookeeper), authentication and authorization.
However, Kafka do not support encryption at rest (do not encrpyt data stored on broker’s disk) out of the box. Common solutions include : encrypting data in producer and decrypting it in consumer or deploying a fully encrypted disk storage.
Environment
There are many tools around Kafka
- Kafka Connect : provides integration with external source and target services (e.g. RabbitMQ, Cassandra) to read / write data from Kafka. In addition, Kafka maintains fault tolerance and scalability for the connectors.
- Confluent REST Proxy: for external clients to talk to Kafka via a RESTful API.
- Confluent Schema Registry: to make data backwards compatible by managing schema versions.
- ksqlDB: is a streaming SQL Engine for Kafka, which can be used for streaming ETL, monitoring, anomaly detection. It leverages Kafka Streams.
- Kafka Streams: API to transform / aggregate streaming data
References
- Confluent on Kafka
- Hussein Nasser on Kafka : includes code examples in node.js