You’ve probably heard git mentioned amongst developers.
But what is it?
Is it related to Github?
How does it work?
There’s too many git commands. How can I remember them all?
This condensed introduction to git starts with explaining git’s underlying concepts so you don’t need to blindly memorize git’s notorious commands anymore.
Installation
Git is a software. So, you need to install them.
- Install git. If you are on Linux or Mac, it should have been pre-installed.
- (Optional) Create a github account.
Burning Question
Before we start, let’s answer some burning questions that I had when first learning git.
Git & GitHub
How is this two related? Git is a Version Control System. We will discuss what it means in a while. GitHub, on the other hand, an application that store git projects on the internet so we can collaborate and share the project with others. Github is a git hosting provider. Other git hosting providers include BitBucket, Gitlab, gitea.
What is git for?

Imagine you are working on an essay and you are writing your first draft and save it as version 0. Then you decide to change a bit, and save it as version 1. You make another change and save it as version 2. Satisfied with the current draft, you decide to ask your professor and a friend for review. Meanwhile, you noticed some grammar mistakes in the essay. You correct them and save it as version 3. The next day, your friend sends you back your draft (based on version 2) with his comments. You combine the grammar changes you’ve made with your friend’s comments to create a version 4. The next week, your professor returns your draft (based on version 2) with a revision. This time, when you tried combining what you have (version 4), with the draft from your professor, you realized that some sentences is missing in one of the documents. Just combining it directly will make the document lose its flow. You decide to take the best of both revisions, and to do so, you manually compare each sentences of the 2 documents and make changes accordingly to create your final submission.
What is git?
As mentioned before, Git is a Version Control System. It’s a system that helps you track different versions of your files. Although it can be used for regular documents, git is particularly helpful in software development where a lot of files are tracked and many people are making changes to the same files at any point in time.
Before we start
How does git store our changes?
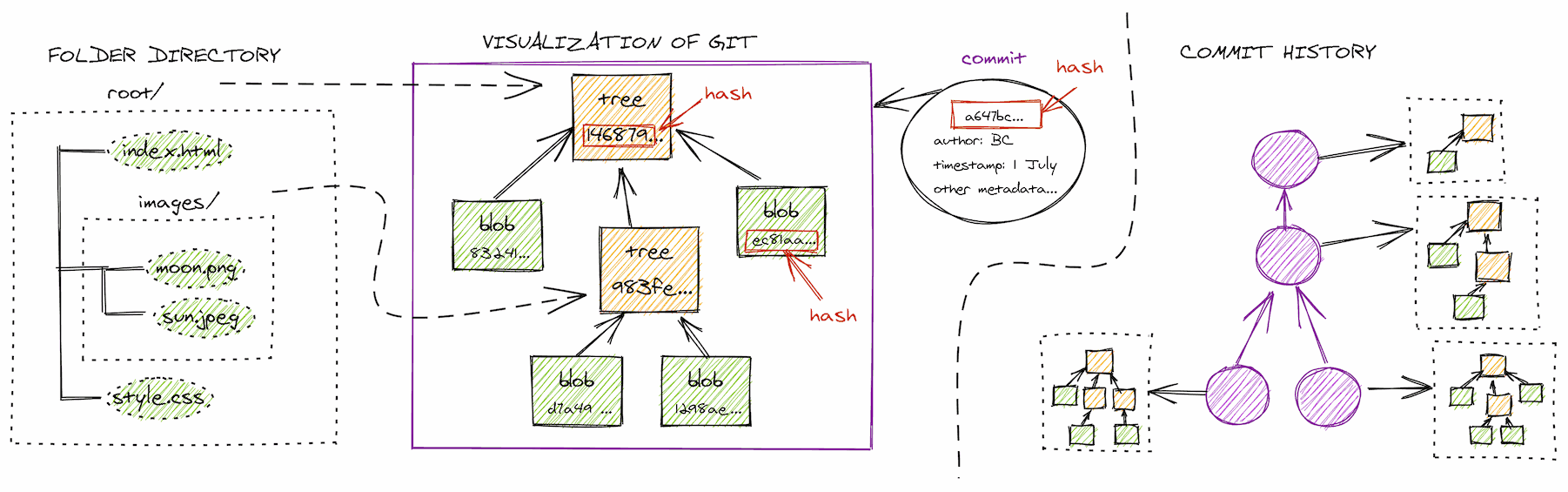
Git stores the state of our directory in objects. There are only 3 types of objects in git: Blobs, Trees and Commits.
- Blob: Every file in a repository is stored as a blob. To uniquely identify a file, git will create a hash based on the contents of the file.
- Tree: A tree containing other trees and blobs.
- Commit: A full snapshot of the contents of your working tree + other metadata. You can remember a commit as a photograph of the tree. Metadatas include commit author, commit time, and commit parent(s). Commit is important as it allows you to travel back in time to see how your documents evolve. In case you make a fatal mistake, such as a bad deployment, git saves you the trouble by making it easy to undo the mistake.
Every object inside a working tree is uniquely identified by git using the SHA1 hash of their contents, which is 40-characters long. When we need to refer to a specific object, it is usually enough to input the first 6 or 7 characters of a hash for git to deterministically identify any object.
Some Definitions
- Repository : A collection of commits.
- Working Tree : the directory where you have content that you want to manage with
git. - tracked / untracked: Tracked files are all files whose revision(s) are managed by git.
- HEAD: HEAD refers to the latest state that is saved to git. When you make changes in your working tree, it will be based on what the HEAD is currently pointing to. We will define HEAD more clearly in later section, when we talk about the concept of branch. For now, this definition shall suffice.
Now that you know why git is good for developing software, lets dive into how to use git.
Working Alone
- To start a git repository from scratch, do
git initon the root folder of your project. This will create a folder named.gitinside your working tree where git will store objects and other references. - Make changes to your working tree. When you want to save your changes, there is 2 step process that you need to do.
- First,
git add <filename(s) or foldername>. This will add your changes to the index. For now, you can add everything in your current folder to the index bygit add .(the last dot is important, it signifies “current folder”) - Then,
git commit.
- First,
How does this 2 step process work?

In git, there is a middleman called index. Sometimes, you might also hear
people refer it as staging area. When you do a git add, the changes you have
made in the working tree (compared to HEAD) are added to the index. the term
add here refers to all changes made in your working tree which includes
creating new files, modifying, ignoring or deleting files.
git commit will then take all the changes recorded by index, apply it to the
state of HEAD, take a snapshot of the new state, and return a hash for the new
snapshot.
Why need git add? Can’t we just git commmit?
Imagine the case where you are fixing 2 bugs in your code, but you want to separate the commits so that you can retrace which code change fixes which bug. With the index, it is easier to do this. You can just add the changes for the first bug, and commit it. Then add the rest of the changes, and make another commit.
Another case will be: Imagine the case where you are debugging some code with a
lot of print statements. When you finally found where the bug is, and fix the
code, you can add only the change that fix the bug to the index, make a commit
and discard the rest of debugging statements via git reset --hard
Understanding the current state
It is important to know the difference
git status: This command helps you understand the current “status” of your working tree. It will show you which file has been modified, untracked or added to index.git diff: This command is similar togit status.git diff --cached, on the other hand, shows you the difference between what’s currently staged in the index compared to your last commit.git log: see all commits made. i.e. see your commit history.git help <command>: There are many options that you can use to modify the result of each command. You can see all available options for each git command by usinggit help. For example, if you would like to see the difference for a specific file, you could dogit diff -- <file or foldername>
Collaboration
Satisfied that git can version changes for you, now you want to collaborate with a friend. Before that we have a couple of things to learn.
Branches, Tags
A branch is simply a move-able pointer to a commit, and it can be easily moved to point to another commit.
git branch: Branches are created usinggit branchcommand, which creates a new label / pointer to the latest commit in your commit history. When you start a git repository, git creates a default branch for you, namedmaster.git checkout <commit or branchname>: Load the contents of a commit or the commit where the branch (a pointer!) is pointing to. When you checkout a commit, all tracked files in your working tree is changed/replaced to match that commit. That’s why git will complain if there are changes that have not been- It is good to note here that people sometimes refer to the action of making a commit as check-in.
- It is usually the case that you want to create a new branch and move to the new branch. You can
git checkout -b <branchname>which is essentially doinggit branch <branchname>andgit checkout <branchname>.
Now that we have discussed the terminology of a branch, we can completely define what a HEAD is.
- HEAD: HEAD is a special pointer to indicate which branch / commit that is currently loaded inside your working tree). Every change you made in the working tree will be compared to the commit that HEAD is pointing to.
- When you make a
commit, git also fast-forwards (move) your current branch and HEAD to point to the new commit. - ☠ A scary note from git: If you
checkouta commit without a branch pointing to it, git will tell you that you are in adetached HEADstate. (scary it might seem, but the good news is git are not in the business of cutting anybody’s head). To create new commits based on the contents of thisdetached HEAD, read more on what git have to tell you.
Having defined a branch, we can easily define a tag. A tag is a fixed
pointer to a commit. We can use tag to give a commit a human-readable name, or
to “tag” a specific commit as a particular version of a software. You can create a tag using git tag <tagname> <commit or object>
REMOTES
Remote repository is a repository that is not your local copy. It can be hosted in a centralized git such as Github, or other person’s computer or even another folder in your own computer.
We can refer to remotes by name. Two most common names are “origin” and “upstream”.
Action Commands
git clone: Create a local copy from a remote with the original repository we copied added as our local copy’s remote.git fetch: Get changes / updates from a remote. When fetched, latest commits are downloaded to our computer and stored separately from our current working tree.git merge: Apply changes fetched to our current working tree.git pull: an alias forgit fetch+git merge. In some cases, such as if you are working collaboratively, you might occasionally face a merge conflict, a situation where git does not know how changes made in two separate line of development should be combined. It usually comes from a change made in the same line of a same file. In this situation, git will leave the decision to us to manually merge the changes.git push: Upload our changes to remote.
Forking
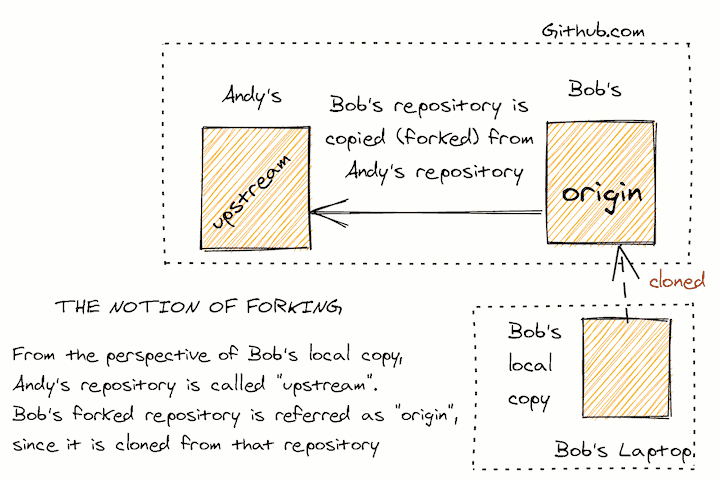
- origin: Origin is a default name for a remote for the “original” git repository that you copy from when you do a git clone.
- fork: fork is similar in essence to clone. It is a name used in GitHub / BitBucket for an operation that copy someone else’s repository to your github account instead of your computer. Fork is useful for making open source contribution
- upstream: Upstream is a remote name that people use to refer to the original source of a forked repository. (Remember, our forked repository is referred to as “origin”)
- How to add remote? You can do
git remote set-url <name of remote> <url>, so in this case, we can dogit remote set-url upstream <url of original repository that we forked from>
Status Commands
You have learned other status commands such as status, diff, and log. For
remotes, your status commands are:
git remote -v: List all remotesgit branch -v: List all branches (both local and remote)
Collaboration Workflows
Collaboration is where centralized git repository hosting plays a part. As you host your repository in the cloud, it serves as a single source of truth that enables your friends or even strangers to collaborate on your code with the same starting point as you.
Right now, the biggest git repository hosting is GitHub and many open-source software repository are hosted there. What is cool about centralized git repository hosting, is that you can peek inside the code of your favorite software, and possibly create a fix for or notify its maintainer of an issue that you face while using it.
In the following sections, whenever you see the word GitHub, you should mentally substitute it with the term centralized git repository hosting which includes GitLab and Bitbucket.
Basic collaboration
Starting a new repository in GitHub You need to create one via their web UI and follow the git commands listed after you create a repository.
- When you first started to collaborate on a repository, you need to do a
cloneof the repository to create a local copy in your computer.
Creating changes and committing
- You can make changes and create a commit as if you are working alone. (it is
addthencommit.) This is possible because git is decentralized in nature. This means, Git stores a local copy of the repository, which will not affect the repository hosted in GitHub before you tell git to sync your changes via apush.
Good Practices
- It is usually good practice to create a new branch from the main development
branch whenever you are making changes that can be categorized into different
topics.
- The main development branch might vary based on how each repository is maintained. Common development branch names are master or dev branch.
- This is to help isolate development (and bugs) to each individual feature.
- Another benefit will be that you can keep updated with other people’s work by syncing your main branch while keeping your changes in a separate branch intact.
- Your new branch can be a feature branch (naming the branch the feature you are going to be working on) or a fix branch (e.g. hotfix-*)
- Do a
git pullbefore you dogit push. This is to resolve any merge conflicts that might occur in a collaboration, so that your changes can be merged cleanly to the main development branch
Contributing to open source projects
Usually, in contributing to open source projects, we fork the repository, make changes to our own copy of the repository, and make a pull request from our copy to the original copy of the repository. A pull request is essentially an accumulation of changes made in our copy. Project maintainers will usually look at the changes and either discuss, accept and merge your changes or ask for changes.
Reviewing a Pull Request
Sam of think-like-a-git.net outlines 3 patterns. I will just link Sam’s explanation here, because I feel I can’t explain them better than him.
Misc commands
git branch -D <branchname>: will delete a branch. It will not interfere with your commit history. Remember, a branch is just a pointer.git remote prune <remotename>: will remove references to non-existing remote branchesgit stash: This command enables you to set the changes you’ve made your working tree aside in a way that you can bring them back later viagit stash applyorgit stash pop. You can think of it as creating a temporary commit. It is particularly useful if you are about tocheckoutanother branch, which will overwrite the changes made in your working tree, so youstashbefore doing your checkout.
Configuring git
Git is highly configurable. To configure git, you can navigate to the root of
your project and change .git/config file or via the git config command.
Other Resources
- https://jwiegley.github.io/git-from-the-bottom-up/
- https://smusamashah.github.io/explain-git-in-simple-words
- https://missing.csail.mit.edu/2020/version-control/
- http://think-like-a-git.net/
- https://danielmiessler.com/study/git/
- https://www.atlassian.com/git/tutorials/
More advanced stuff
As I also use this note personally, here are some more advanced stuff that I am starting to use. I might move it to a separate post if I feel its contents merit one.
GIT SUBMODULE SYNC with your non-default git account
git clone git@work_user1.github.com:work_org/repo_name.git- Change urls in
.gitmodulesfile to have your work user subdomain (e.g.git@work_user1.github.com:work_org/repo_name.git) git submodule syncgit submodule --init --recursivecdto each submodule and dogit reset --hard- Make sure each submodule that you need is not empty.